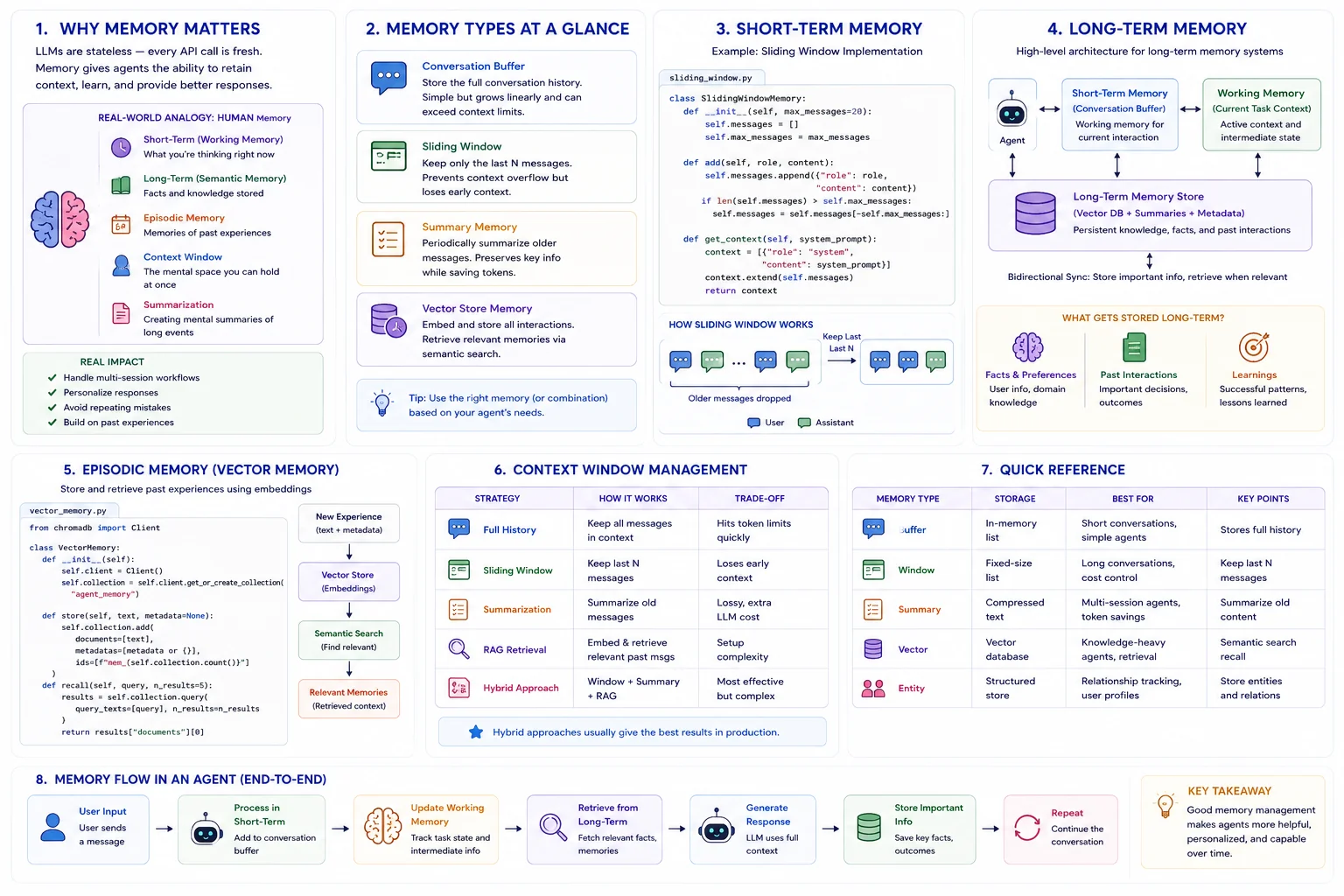
Why Memory Matters
Why Memory Matters
The Problem: LLMs are stateless -- each API call starts fresh with no memory of previous interactions. Without memory, agents cannot maintain context across conversations.
The Solution: Memory systems give agents the ability to retain conversation history, store important facts, and recall relevant past experiences -- making them more effective over time.
Real Impact: Memory-enabled agents can handle multi-session workflows, personalize responses, and avoid repeating mistakes.
Real-World Analogy
Think of agent memory like human memory systems:
- Short-Term = Your working memory during a conversation
- Long-Term = Facts and knowledge stored for later recall
- Episodic = Memories of specific past experiences and outcomes
- Context Window = How much you can hold in mind at once
- Summarization = Creating mental summaries of long events
Memory Types at a Glance
Conversation Buffer
Store the full conversation history. Simple but grows linearly and can exceed context limits.
Sliding Window
Keep only the last N messages. Prevents context overflow but loses early context.
Summary Memory
Periodically summarize older messages. Preserves key information while saving tokens.
Vector Store Memory
Embed and store all interactions. Retrieve relevant memories via semantic search.
Short-Term Memory
class SlidingWindowMemory:
def __init__(self, max_messages=20):
self.messages = []
self.max_messages = max_messages
def add(self, role, content):
self.messages.append({"role": role, "content": content})
if len(self.messages) > self.max_messages:
self.messages = self.messages[-self.max_messages:]
def get_context(self):
context = [{"role": "system", "content": self.system_prompt}]
context.extend(self.messages)
return contextLong-Term Memory
Episodic Memory
from chromadb import Client
class VectorMemory:
def __init__(self):
self.client = Client()
self.collection = self.client.get_or_create_collection("agent_memory")
def store(self, text, metadata=None):
self.collection.add(
documents=[text],
metadatas=[metadata or {}],
ids=[f"mem_{self.collection.count()}"]
)
def recall(self, query, n_results=5):
results = self.collection.query(
query_texts=[query], n_results=n_results
)
return results["documents"][0]Context Window Management
| Strategy | How It Works | Trade-off |
|---|---|---|
| Full History | Keep all messages | Hits token limits quickly |
| Sliding Window | Keep last N messages | Loses early context |
| Summarization | Summarize old messages | Lossy, extra LLM cost |
| RAG Retrieval | Embed and search past messages | Setup complexity |
| Hybrid | Window + summary + RAG | Most effective but complex |
Quick Reference
| Memory Type | Storage | Best For |
|---|---|---|
| Buffer | In-memory list | Short conversations |
| Window | Fixed-size list | Long conversations |
| Summary | Compressed text | Multi-session agents |
| Vector | Vector database | Knowledge-heavy agents |
| Entity | Structured store | Relationship tracking |