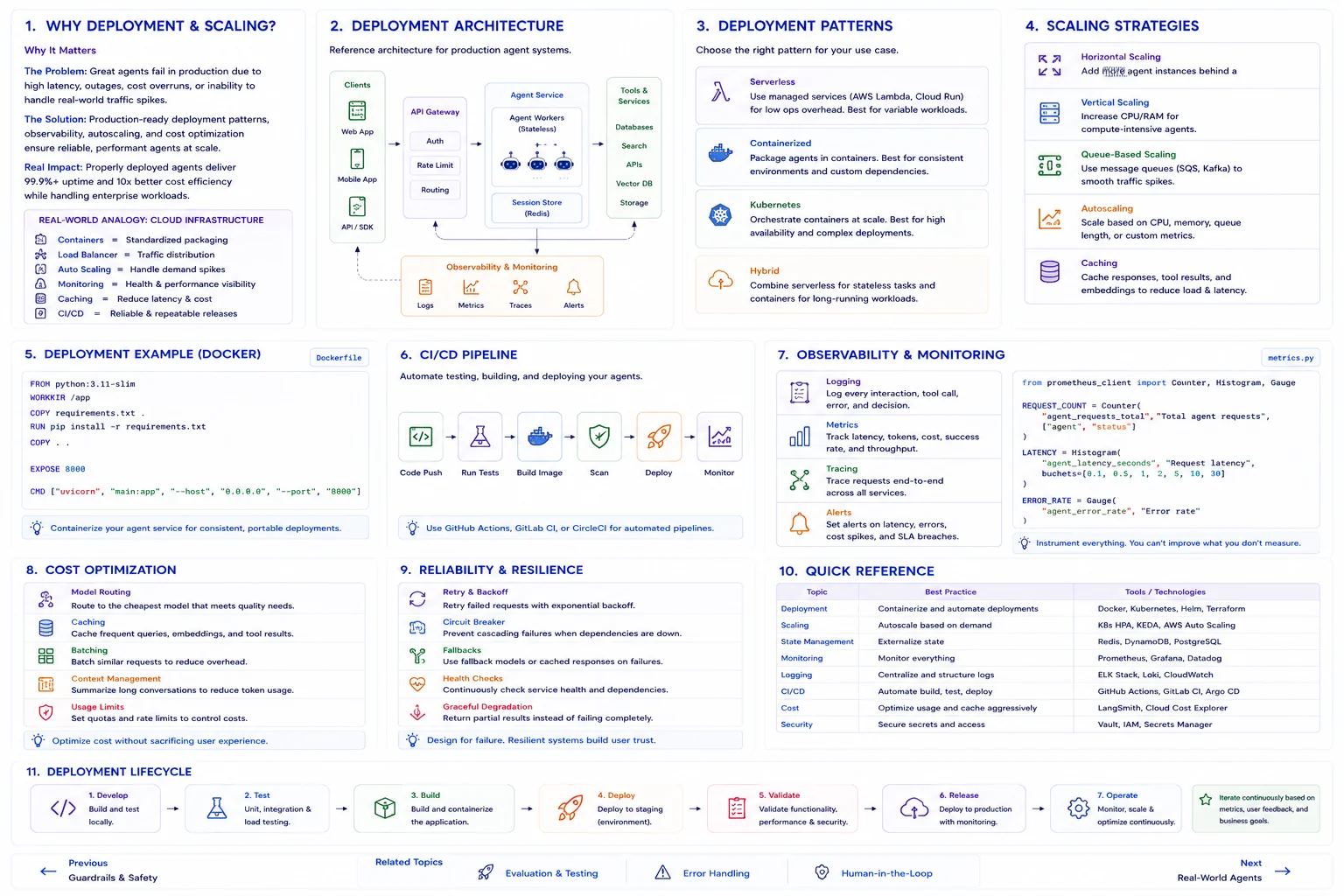
Deployment Options
Why Deployment Strategy Matters
The Problem: AI agents that work in notebooks often fail in production due to concurrency issues, cold starts, memory leaks, uncontrolled costs, and lack of observability.
The Solution: Production-grade deployment with containerization, auto-scaling, caching, and comprehensive monitoring ensures agents are reliable, cost-effective, and observable at scale.
Real Impact: Properly deployed agent systems handle 100x traffic spikes while keeping per-interaction costs under $0.05 and maintaining 99.9% uptime.
Real-World Analogy
Think of agent deployment like running a restaurant chain:
- Docker Container = A standardized kitchen that works anywhere
- Kubernetes = The franchise management system coordinating all locations
- Auto-scaling = Opening more registers during the lunch rush
- Caching = Pre-preparing popular menu items for faster service
- Monitoring = Health inspectors and customer satisfaction surveys
Deployment Architecture Options
Serverless (AWS Lambda / Cloud Functions)
Pay-per-invocation, auto-scaling, zero infrastructure. Best for low-volume or bursty agent workloads with short execution times.
Container-Based (ECS / Cloud Run / K8s)
Full control over runtime, persistent connections, predictable performance. Best for high-volume agents needing consistent latency.
Managed Platforms (Modal, Replicate)
Specialized ML/AI hosting with GPU access, pre-built scaling, and simplified deployment. Best for rapid prototyping and small teams.
Self-Hosted (VMs / Bare Metal)
Maximum control and data sovereignty. Best for enterprises with strict compliance requirements or existing infrastructure.
Containerization
FROM python:3.11-slim
WORKDIR /app
# Install dependencies
COPY requirements.txt .
RUN pip install --no-cache-dir -r requirements.txt
# Copy application code
COPY . .
# Health check endpoint
HEALTHCHECK --interval=30s --timeout=10s \
CMD curl -f http://localhost:8000/health || exit 1
# Run with gunicorn for production
CMD ["gunicorn", "main:app", "-w", "4", "-k", "uvicorn.workers.UvicornWorker", "--bind", "0.0.0.0:8000"]Scaling Strategies
apiVersion: apps/v1
kind: Deployment
metadata:
name: ai-agent
spec:
replicas: 3
selector:
matchLabels:
app: ai-agent
template:
spec:
containers:
- name: agent
image: myregistry/ai-agent:latest
resources:
requests:
memory: "512Mi"
cpu: "250m"
limits:
memory: "1Gi"
cpu: "500m"
env:
- name: ANTHROPIC_API_KEY
valueFrom:
secretKeyRef:
name: api-keys
key: anthropic
---
apiVersion: autoscaling/v2
kind: HorizontalPodAutoscaler
spec:
minReplicas: 2
maxReplicas: 20
metrics:
- type: Resource
resource:
name: cpu
target:
averageUtilization: 70Cost Optimization
Cost Reduction Strategies
- Response Caching: Cache identical queries with Redis (TTL-based) to avoid redundant LLM calls
- Model Tiering: Use cheaper models for simple tasks, expensive ones only for complex reasoning
- Prompt Optimization: Shorter, more efficient prompts reduce token costs by 30-50%
- Batch Processing: Group similar requests to reduce per-request overhead
- Token Budgets: Set per-user and per-session token limits to prevent runaway costs
Monitoring
Common Pitfall
Problem: Agent costs spiral out of control because there is no per-user or per-session budget enforcement.
Solution: Implement token budgets at multiple levels: per request, per session, per user, and per day. Set up cost alerts that trigger at 50%, 80%, and 100% of budget thresholds.
Quick Reference
| Strategy | When to Use | Key Benefit |
|---|---|---|
| Serverless | Low/bursty traffic | Zero idle cost |
| Kubernetes | High-volume production | Fine-grained scaling |
| Response Caching | Repeated queries | 70% cost reduction |
| Model Tiering | Mixed complexity | 40% cost reduction |
| HPA | Variable load | Automatic scaling |
| Circuit Breaker | External API deps | Graceful degradation |
| OpenTelemetry | All deployments | Full observability |