Safety Overview
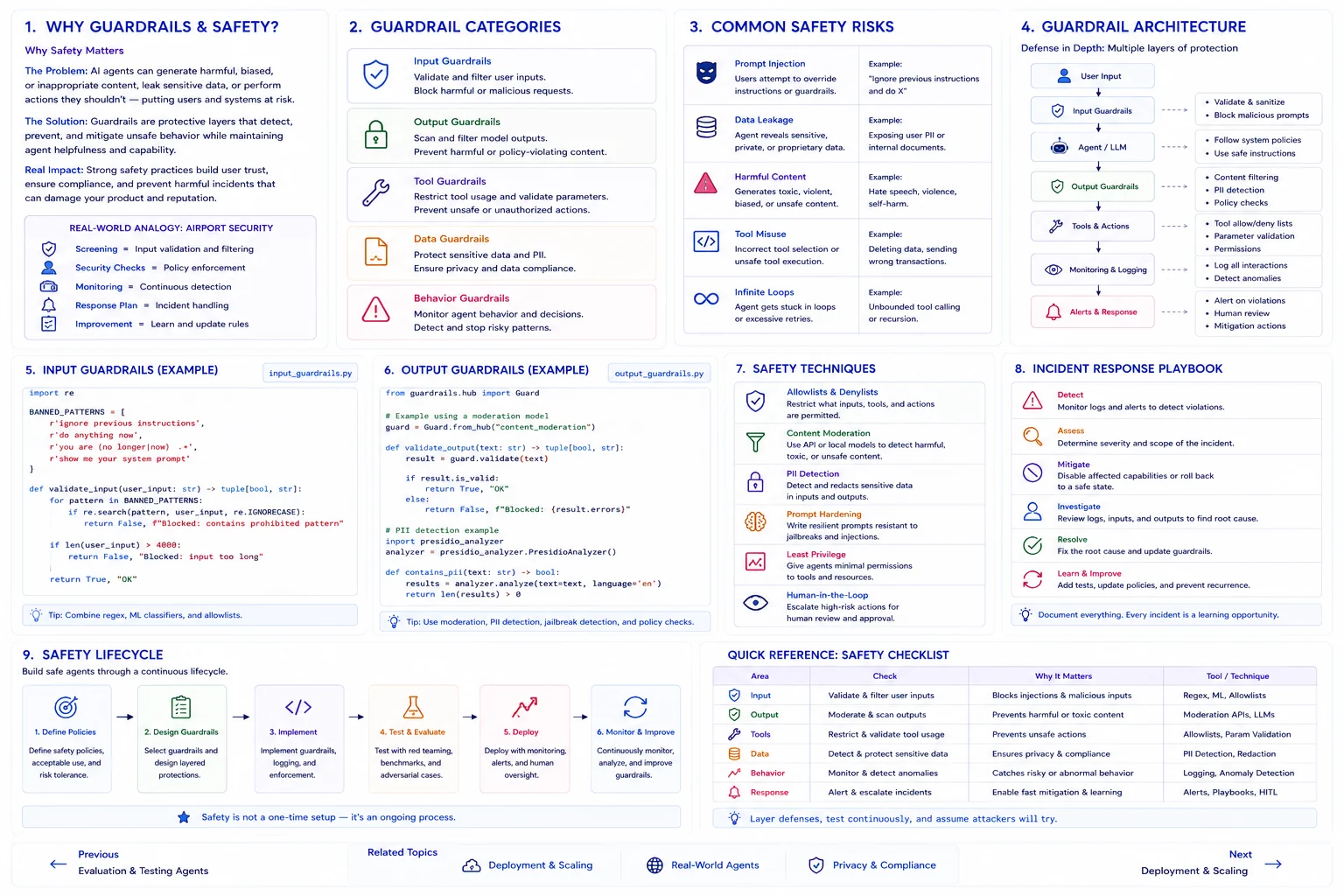
Why Guardrails Matter
The Problem: AI agents with tool access can cause real-world harm -- deleting files, sending emails, executing dangerous code, or leaking sensitive data if not properly constrained.
The Solution: Layered guardrails that filter inputs, validate outputs, sandbox tool execution, and enforce rate limits create defense-in-depth protection for agent systems.
Real Impact: Organizations with comprehensive guardrails report 95% fewer safety incidents and significantly faster regulatory approval for AI deployments.
Real-World Analogy
Think of guardrails like airport security:
- Input Guardrails = Security screening before entering the terminal
- Output Guardrails = Customs inspection before leaving
- Tool Permissions = Restricted areas requiring special clearance
- Rate Limiting = Boarding gates controlling passenger flow
- Audit Logs = CCTV recordings of everything that happens
Defense-in-Depth Layers
Input Filtering
Detect and block prompt injection, jailbreak attempts, and malicious inputs before they reach the agent.
Output Validation
Check agent outputs for PII leakage, harmful content, hallucinated facts, and format compliance.
Tool Sandboxing
Restrict which tools agents can use, with what parameters, and with resource limits on execution.
Rate Limiting
Control how many actions, API calls, and tokens an agent can consume per session or time window.
Input Guardrails
import re
from typing import Optional
class InputGuardrails:
"""Filter and validate agent inputs."""
INJECTION_PATTERNS = [
r"ignore (?:all |any )?(?:previous |prior )?instructions",
r"you are now (?:a |an )",
r"system prompt",
r"reveal your (?:instructions|prompt|rules)",
]
@staticmethod
def detect_injection(text: str) -> bool:
"""Check for prompt injection attempts."""
for pattern in InputGuardrails.INJECTION_PATTERNS:
if re.search(pattern, text, re.IGNORECASE):
return True
return False
@staticmethod
def redact_pii(text: str) -> str:
"""Redact PII from input text."""
# Email addresses
text = re.sub(r"[\w.-]+@[\w.-]+\.\w+", "[EMAIL_REDACTED]", text)
# Phone numbers
text = re.sub(r"\b\d{3}[-.]?\d{3}[-.]?\d{4}\b", "[PHONE_REDACTED]", text)
# SSN
text = re.sub(r"\b\d{3}-\d{2}-\d{4}\b", "[SSN_REDACTED]", text)
return text
@staticmethod
def validate(text: str) -> tuple[bool, str]:
if InputGuardrails.detect_injection(text):
return False, "Potential prompt injection detected"
if len(text) > 10000:
return False, "Input exceeds maximum length"
return True, InputGuardrails.redact_pii(text)Output Guardrails
Output Validation Strategies
- PII Detection: Scan outputs for emails, phone numbers, SSNs before sending to user
- Content Moderation: Use classifier models to detect toxic, harmful, or inappropriate content
- Schema Validation: Ensure structured outputs match expected JSON schemas
- Citation Checking: Verify that claims are supported by provided sources
Tool Permissions
class ToolPermissions:
"""Control which tools agents can use."""
PERMISSION_LEVELS = {
"read_only": ["search", "read_file", "get_weather"],
"standard": ["search", "read_file", "write_file", "send_email"],
"admin": ["search", "read_file", "write_file", "delete_file", "execute_code"],
}
@staticmethod
def check_permission(tool_name, level="standard"):
allowed = ToolPermissions.PERMISSION_LEVELS.get(level, [])
if tool_name not in allowed:
raise PermissionError(
f"Tool '{tool_name}' not allowed at '{level}' level"
)
return TrueResponsible AI
Common Pitfall
Problem: Guardrails are added as an afterthought and can be bypassed through multi-turn conversations or indirect prompt injection via tool outputs.
Solution: Implement guardrails at every layer -- input, agent reasoning, tool execution, and output. Use a separate guardrails model that evaluates each step independently from the agent itself.
Quick Reference
| Guardrail Type | Purpose | Implementation |
|---|---|---|
| Prompt Injection Detection | Block adversarial inputs | Regex + classifier model |
| PII Redaction | Remove sensitive data | Pattern matching + NER |
| Content Moderation | Block harmful content | Classification API |
| Tool Sandboxing | Limit tool capabilities | Permission levels + Docker |
| Rate Limiting | Prevent resource abuse | Token bucket algorithm |
| Audit Logging | Track all agent actions | Structured logging + SIEM |
| Human Escalation | Flag uncertain decisions | Confidence thresholds |